共分散行列に全部値が詰まった一般の二次元ガウス関数の最小二乗法の実装メモ.
scikit-learnのsklearn.mixture.GaussianMixtureを用いてEMアルゴリズムにより混合ガウス分布を推定するプログラムのサンプルはあちこちで見かけるけど最小二乗法が意外と無い.
EMアルゴリズムと最小二乗法の違いは,EMアルゴリズムはデータ点$(x_i, y_i)$からガウス分布のパラメータを推定するのに対して,最小二乗法はデータ点$(x_i, y_i, z_i)$からガウス分布のパラメータを推定する部分.
最小二乗法の関数scipy.optimize.leastsqの使い方とか独特なのでちょっと手こずったから忘れないように.
二次元ガウス関数を描画
二次元ガウス関数の定義
まずは肝心のガウス関数.
ベクトル・行列の表記だけを見ると二次元でも多次元でも同じなので,とりあえず多次元版を載せておく.
\begin{equation}
\newcommand{\vec}{\boldsymbol}
f(\vec{x}) = \frac{1}{\sqrt{(2\pi)^n \left|\Sigma\right|}}\exp
\left \{-\frac{1}{2}{} (\vec{x}-\vec{\mu})^T\,{\Sigma}^{-1} (\vec{x}-\vec{\mu}) \right\}
\end{equation}
でもやっぱり成分表記しないとイメージしにくいので二次元版($n=2$)のために成分も載せておく,
ちなみに$\sigma_{xy}=0$のときは,$x$軸か$y$軸方向にガウス関数が広がりを持っていて,$\sigma_{xy}\neq 0$の時はそれが回転したような形になっている.
\begin{equation}
\vec{\mu}=
\left[
\begin{array}{c}
\mu_x \\
\mu_y
\end{array}
\right]
,\ \ \
\Sigma = \left[
\begin{array}{cc}
\sigma_x^2 & \sigma_{xy} \\
\sigma_{xy} & \sigma_y^2
\end{array}\right]
\end{equation}
これをPythonコード化したものがこれ↓↓.
leastsqをが最小二乗法の関数.
「@」は数学で習う行列とベクトルの積.横ベクトルと縦ベクトルを内積とって左辺の要素を計算するあれ.
A @ Bを別の表記にすればnp.dot(A, B)です.
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
def gaussian(x,mu,sigma):
det = np.linalg.det(sigma)
inv = np.linalg.inv(sigma)
n = x.ndim
return np.exp(-np.diag((x - mu)@inv@(x - mu).T)/2.0) / (np.sqrt((2 * np.pi) ** n * det))
二次元ガウス関数の計算
この関数が正しく実装できているか確認するために可視化する.
可視化するためにmeshgridによって$(x,y)$の密な点配列を生成する.
XYは$40\times40=1600\,$個の二次元座標列を$1600\times2$の行列として成形されている.
x = np.linspace(0, 40,40)
y = np.linspace(0, 40,40)
X, Y = np.meshgrid(x, y)
XY = np.c_[X.ravel(), Y.ravel()]
これが関数本体の計算部分.
最初に適当なパラメータ$\vec{\mu}$や$\Sigma$の値を設定している.
gaussian関数の戻り値Zは,$1600\times1$のベクトルなので,描画用に元の$40\times40$の行列に戻している.
# パラメータ設定
mu = np.array([25,15])
sigma_x = 8.0
sigma_xy = 3.0
sigma_y = 3.0
sigma = np.array([
[sigma_x**2, sigma_xy],
[sigma_xy, sigma_y**2]])
# ガウス関数の計算
Z = gaussian(XY, mu, sigma)
z = Z.reshape(X.shape)
# ガウス関数の計算
max = np.max(Z)
min = np.min(Z)
print("min: %f, max: %f" % (min, max))
最大値,最小値の結果は次のとおり.
min: 0.000000, max: 0.006615
二次元ガウス関数の描画
ここは普通のグラフの描画と同じなので特に説明の必要はないかも.
x軸,y軸の範囲を[0, 39]しているのは40を最大にすると空白の1画素ができてしまったから.
fig = plt.figure(figsize = (6, 6))
plt.xlim([0, 39])
plt.ylim([0, 39])
plt.imshow(z, cmap="jet", vmin=min, vmax=max)
plt.subplots_adjust(left=0.04, right=1, bottom=0.04, top=1)
plt.savefig("gauss.png")
plt.show()
二次元ガウス関数の最小二乗法
データ点の生成
データ点は乱数で生成してみる.素なグリッドでも良い.
$(x,y)$だけ乱数でテータ点$(x_i,y_i)$を生成して,各点に対して$f(x_i,y_i)$を計算してそこに正規分布の誤差を加えてみる.正規分布の分散はかなり小さい値にしないといけない.そもそも,二次元ガウス関数の最大値もかなり小さいので.
n = 1024*768//2**8
x_rand = np.random.random_sample(n)*40
y_rand = np.random.random_sample(n)*40
xy_rand = np.c_[x_rand.ravel(), y_rand.ravel()]
z_rand = gaussian(xy_rand, mu, sigma)+ np.random.normal(0.0, 0.0001, xy_rand.shape[0])
ここが可視化部分.分かりやすいように上の画像をα値0.5の半透明な背景としている.
fig = plt.figure(figsize = (6, 6))
plt.xlim([0, 39])
plt.ylim([0, 39])
plt.imshow(z, cmap="jet", alpha=0.5)
plt.scatter(x_rand, y_rand, c = z_rand, cmap="jet", edgecolors="black")
plt.subplots_adjust(left=0.04, right=1, bottom=0.04, top=1)
plt.savefig("gauss_data.png")
最小二乗法
最小二乗法には評価関数を定義しないといけない.
評価関数はデータ$z_i$とデータ点$(x_i,y_i)$でのガウス関数の値$f(x_i, y_i)$の差の二乗和.
ただし,leastsqではLevenberg-Marquardt法が使われているので与える必要があるのは$\epsilon_i = z_i - f(x_i, y_i)$の部分だけ.
これがn個あるのでxdataにはn$\times$2の行列が,zdataにはn$\times$1の行列が与えられるはず.
paramsは5次元ベクトルで,前の2要素に[$\mu_x, \mu_y$],後の3要素[$\sigma_x, \sigma_xy, \sigma_y$]が格納されているとする.
#評価関数定義
def error(params, xdata, zdata):
mu = params[0:2]
sigma = np.array([
[params[2], params[3]],
[params[3], params[4]]
])
return zdata - gaussian(xdata, mu, sigma)
最小二乗法のleastsq関数に与えるのは評価関数errorだけでなく初期パラメータx0,データargsを与えないといけない.
初期パラメータは上でテストしたときの値(真値)に適当な誤差2.0と1.5を加えて代入.
データはn$\times$2のxy_randとn$\times$1のz_randを与えてそれぞれxdata,zdataに代入させる.
# パラメータを1次元ベクトル化
mu_init = mu+2
sigma_init = sigma.reshape(4)+1.5
params = np.array(empty(5)
params[0:2] = mu_init
params[2:] = np.array([sigma[0,0], sigma[0, 1], sigma[1, 1]])
# 最小二乗法
results = leastsq(error, x0=params, args = (xy_rand, z_rand))
print(results[0])
これが結果.
[25.04568978 14.93655215 61.81134792 -1.25051091 5.7730626 9.1594342 ]
分かりにくいので$\vec{\mu}$と$\sigma_x, \sigma_y$に分けて表示してみる.
mu_est = params_est[0:2]
sigma_est = params_est[2:].reshape(2,2)
print("mu:")
print(mu_est)
print("sigma:")
print(sigma_est)
print("sigma_x: %f" % np.sqrt(sigma_est[0,0]))
print("sigma_y; %f" % np.sqrt(sigma_est[1,1]))
mu:
[25.11389534 14.9731751 ]
sigma:
[[66.22148794 3.23015128]
[ 3.23015128 9.05173089]]
sigma_x: 8.137659
sigma_y: 3.008609
sigma_xy: 3.230151
真値は$\vec{\mu}=[25, 15]^T$なの中心位置は大体あってる.
$(\sigma_x, \sigma_{xy}, \sigma_y)=(8.0, 3.0, 3.0)$についてもおおよそ正しい.
描画して確認
ここからは最初の繰り返し.
求まったパラメータを使って再度ガウス関数を描画するだけ.
XYだけは使い回せる.ぱっと見近い結果だし問題ないかな.
param_est = results[0]
# 推定されたパラメータをセットする
mu_est = params_est[0:2].reshape(2)
sigma_est = params_est[2:6].reshape(2,2)
# ガウス関数計算
Z_est = gaussian(XY, mu_est, sigma_est)
z_est = Z_est.reshape(X.shape)
# 描画
fig = plt.figure(figsize = (6, 6))
plt.xlim([0, 39])
plt.ylim([0, 39])
plt.imshow(z_est, cmap="jet", vmin=min, vmax=max)
plt.subplots_adjust(left=0.04, right=1, bottom=0.04, top=1)
plt.savefig("gauss_est.png")
plt.show()
推定結果の誤差評価
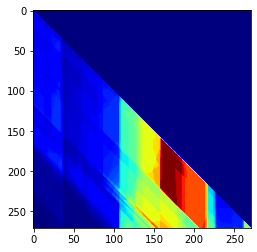
真の分布zと推定されたガウス分布z_estとの差を調べてみる.
これには単純に二つの差の画像を作って二乗和を計算してみる.
E = np.abs(z_est - z)
fig = plt.figure(figsize = (6, 6))
plt.xlim([0, 39])
plt.ylim([0, 39])
plt.subplots_adjust(left=0.04, right=1, bottom=0.04, top=1)
plt.imshow(E, cmap="jet")
誤差の分布が変な形になっているけど,平均値は1.109483e-05であり,加えた誤差の標準偏差0.0001=(1.0e-04)よりも小さい.なので上手くいったということにしておく.
e = np.sum(E)/E.size
print(e)
1.1094833018535245e-05